Elasticsearchは、リアルタイムに分散検索および解析ができる、クラウド環境によくフィットしたエンジンです。ドキュメント指向で、事前にスキーマ定義が不要であり、structured、unstructured、time-seriesといったクエリを柔軟にサポートし、他のアプリケーションや、特にKibanaを含むヴィジュアライゼーションツールの基盤としても動作します。
本日、私たちは新しい、Amazon Elasticsearch Service(略称はAmazon ES)をローンチしました。これによりAWS Management Consoleを使ってスケーラブルなElasticsearchクラスタを数分で構築することが可能になります。クライアントからの接続先をAmazon ESクラスタのエンドポイントに設定することで、データの投入、プロセッシング、解析、ヴィジュアライズを短時間に行うことができます。
ドメインの作成
それでは早速、Amazon ESのドメインを作成してみましょう(AWS Command Line Interface、AWS Tools for Windows PowerShell、Amazon Elasticsearch Service APIを利用することも可能です)。シンプルにGet Startedボタンを押した後、ドメイン名を入力しましょう(今回はmy-es-clusterという名前にします):
インスタンスタイプとインスタンス数を選択します(必要であれば後から変更することが可能です):
こちらが適切なインスタンスタイプを選択する際に参考にしていただきたいガイドラインになります。
- T2 - 開発およびテスト(dedicated masterノードにも適しています)
- R3 - Read-heavyもしくは複雑なクエリ(例えばnested aggregations)
- I2 - High-write、Large-scaleなデータの格納
- M3 - 一般的なreadとwrite
Enable dedicated masterのチェックを入れると、Amazon ESはクラスタ管理用に独立したmasterノードを構築します。masterノードはドキュメントデータを保持せず、クラスタの管理に専念します。クラスタのスタビリティを高めるため、最低3つのmasterノードを指定することを推奨しています。また、スプリットブレインのシナリオを避けるために、masterノード数には常に奇数の値を設定しましょう。
Enable zone awarenessのチェックを入れると、Amazon ESは可用性の向上のため、リージョン内の複数のアベイラビリティゾーンにノードを分散します。こちらを選択する場合、ElasticsearchのIndex APIでレプリカのセットアップをする必要があります。また、新しいインデックスを構築する際は同じAPIを用いることが可能です(詳細はこちら)。
今回はEBS General Purpose (SSD)をdataノード用に選択します。インスタンスストアや他のタイプのEBSボリュームを選択することも可能です。EBSを利用することによって大量データの格納を少ない数のインスタンスでまかなうことができます。但し、書き込みのパフォーマンスはインスタンスストレージの方が効率的です。大きなデータセットを扱うような場合はI2インスタンスを利用することもできます(各ノード毎に1.6テラバイトのSSDストレージを保持します)。
次に、アクセスポリシーを設定します。今回はシンプルにテストするためにwide-openな設定になっておりますのでご了承ください(このような設定をクラスターに利用しないでくださいね)。IP-basedやuser-basedなテンプレートおよび、より制限的なポリシーを作成するウィザードを利用することが可能です。
最後に、設定をレビューしてConfirm and createを押して完了です。
クラスターは数分のうちに作成され、Elasticsearch Serviceダッシュボードに表示されます(Searchable documentsが4になっているのは、このスクリーンショットを撮る前にいくつかドキュメントを追加したためです)。
ドメインの作成に関しては以上です!
ドキュメントのロード
Elasticsearchに関してこのブログポストを書くまでに前提知識はありませんでしたが、更に試さずにはいられません。以下のステップは Having Fun: Python and Elasticsearch, Part 1 に沿って行ったものです。Python library for Elasticsearchをインストールして、クラスタのエンドポイントを確認するためにAWS Management Consoleに戻ります。
上記のブログに従ってステータスチェックを行ったところ全て想定通りに稼働しているようです。そしてPythonのコードをファイルにペーストして保存後、実行してサンプルデータを投入します。すると新しいインデックスがコンソール上で確認できました。
とても簡単です!
ドキュメントの検索
データの投入に成功したら、クラスタに対するKibanaのリンクをクリックして、何かできるか見ていきましょう。
Kibana (バージョン4) がブラウザの新しいタブに表示されます。上記のpostsというインデックスを設定してみましょう。
するとKibana 上でフィールドの確認をすることができました。
更にここからKibanaを使ってデータをヴィジュアライズすることができます(もし私に時間があって何をすべきか分かっていればやってみるのですが…)。
また、Kibanaのバージョン3も利用可能です。アクセスするには _plugin/kibana3/ をクラスタのエンドポイントの後に追加するだけです。
他にも良いことが沢山あります
CLI( aws es update-elasticsearch-domain-configuration )、API( UpdateElasticsearchDomainConfig )もしくはコンソールを使ってクラスタをスケールさせることが出来ます。Amazon ESは新しい設定に従って、新しいクラスタを構築し、データをダウンタイム無しにコピーします。
本日のAmazon ESのローンチで、CloudWatch Logsとのインテグレーション機能もローンチします。あらかじめAmazon ESのドメインを作成しておき、CloudWatch Logsのコンソールにて Subscribe to Lambda / Amazon ES を選択し、ウィザードに従って設定をしていきます。
ウィザードにてAmazon ESに取り込むログのフィルタリングのパターンを設定できます(こちらの設定はオプショナルですが、1つを選択することでログに対してスキーマ定義を可能にします)。以下が、ログをAmazon ESにログを流しこんでKibanaのダッシュボードでログを参照する際の設定のサンプルです。
- VPC Flow Dashboard – こちらのフィルタパターンをご利用ください
[version, account_id, interface_id, srcaddr, dstaddr, srcport, dstport, protocol, packets, bytes, start, end, action, log_status]
- Lambda Dashboard – こちらのフィルタパターンをご利用ください
[timestamp=*Z, request_id="*-*", event]
- CloudTrail Dashboard – JSON formで設定されているのでフィルタパターンの設定は不要です
Amazon ESは ICU Analysis pluginおよび Kuromoji Analysis pluginをサポートします。こちらはElasticsearchのMapping APIを使って設定を行うことが可能です。Amazon ESは現状、商用であるShieldやMarvelのようなプラグインのサポートは行っておりませんが、AWS Identity Access Management (IAM) や CloudWatch を利用することで、そういったプラグインで提供される機能をサポートします。
Amazon ESは自動的にクラスタのスナップショットを毎日取得し、それを14日間保持します。我々にご連絡いただくことでこちらのバックアップからあなたのクラスタへリストアすることが可能です。バックアップの時間帯は “automated snapshot hour” からお選びいただくことができます。また、Elasticsearch Snapshot APIを使ってクラスタのスナップショットをS3バケットに保存することが可能で、取得したスナップショット(Amazon ESもしくはself-managed)をS3バケットからAmazon ESのクラスタへリストアすることができます。
Amazon ESドメインは自身のステータスをCloudWatchに保存します。これらの17のメトリクスをAmazon ESのコンソールのモニタリングタブもしくはCloudWatchのコンソールで参照することが出来ます。クラスタのステータスメトリクス (green, yellow, red) はクラスタのステータスを示します: green は全てのshardがノードにアサインされている状態; yellow は少なくとも1つのレプリカシャードがどのノードにもアサインされていない状態; red は少なくとも1つのプライマリシャードがノードにアサインされていない状態。よくある事象としては、1ノードだけのクラスタを作って、レプリケーションの設定が1の場合(Logstashのデフォルト)にステータスが yellow になっている、というものです。こちらをシンプルにフィックスする手段としては、もう1つのノードをクラスタに追加することが挙げられます。
CPU Utilization はリクエストプロセッシング(readもしくはwrite)がダイレクトに関連する部分であり、もしこのメトリクスが高い場合はインスタンスを追加し、レプリケーションの数を増やしたり、追加でパラレルなプロセッシングを可能にする等の対処をすることができます。同様にJVMのメモリ逼迫に関しても、インスタンスを追加する、もしくは、R3といったメモリが潤沢なリソースを選択するといったことが可能です。CloudWatchのアラームをこれらのメトリクスに対して作成し、10%から20%のフリーStorageおよびフリーCPUを随時確保しておくことをおすすめします。
今からご利用可能です
Amazon ESクラスタは以下のリージョンで利用することが可能です。もちろん東京リージョンも含まれています!US East (Northern Virginia)、US West (Northern California)、US West (Oregon)、Asia Pacific (Tokyo)、Asia Pacific (Singapore)、Asia Pacific (Sydney)、South America (Brazil)、Europe (Ireland)、Europe (Frankfurt)
AWS クラウド無料利用枠の期間中であれば t2.micro.elasticsearchを毎月750時間、10GBのMagneticもしくはSSD-BackedのEBSストレージと共に無料でお使いいただくことが出来ます。
— Jeff;
翻訳: 篠原 英治
原文: https://aws.amazon.com/blogs/aws/new-amazon-elasticsearch-service/
















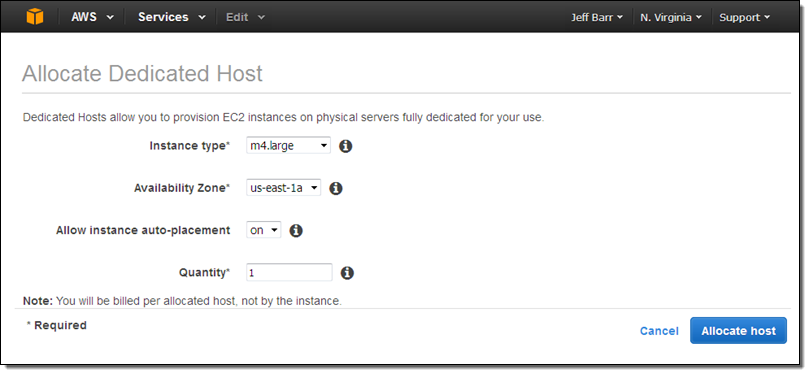
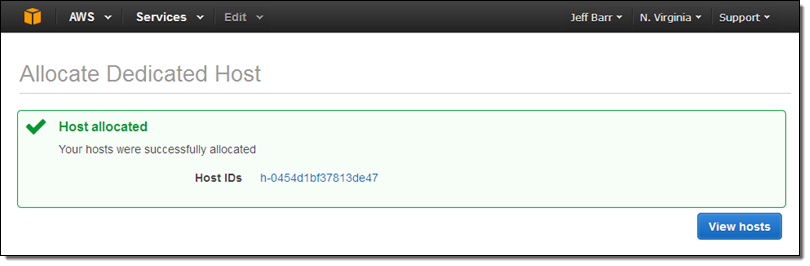
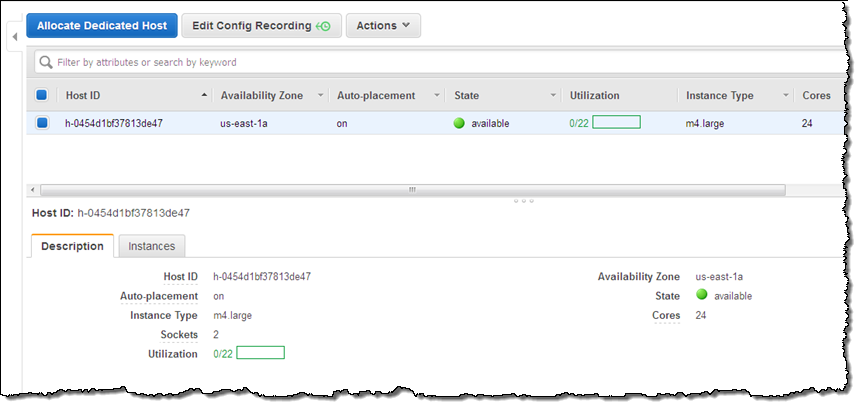
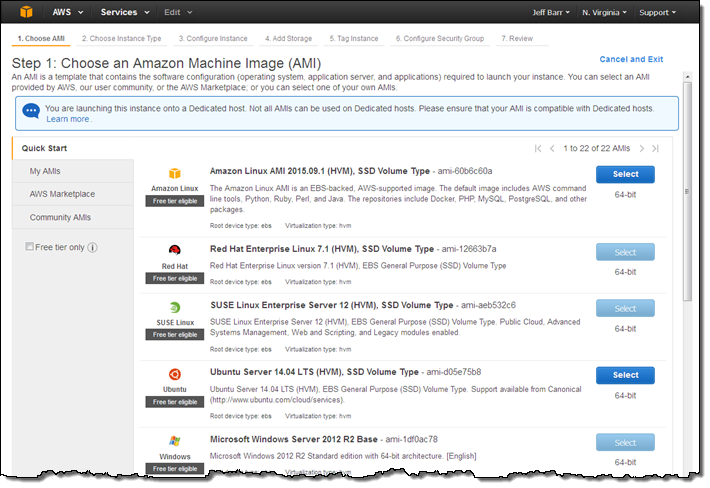
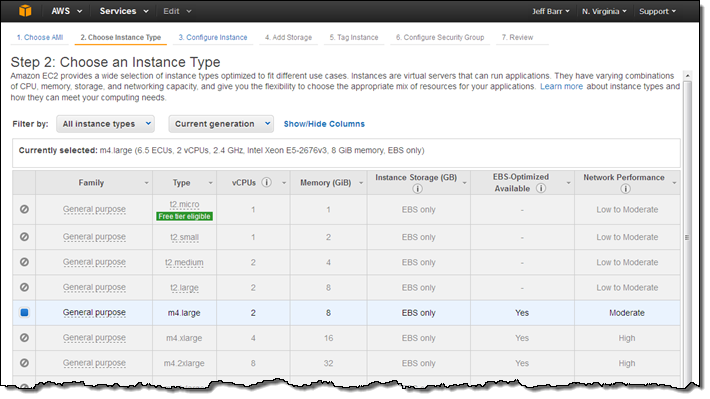
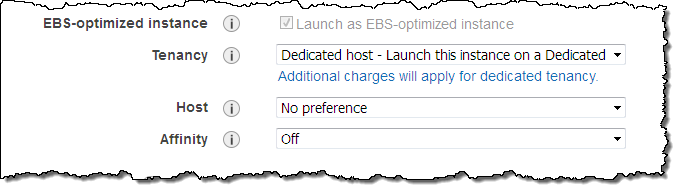
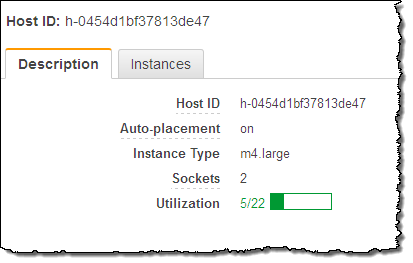
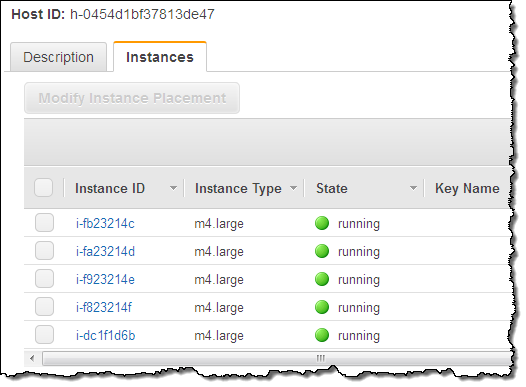
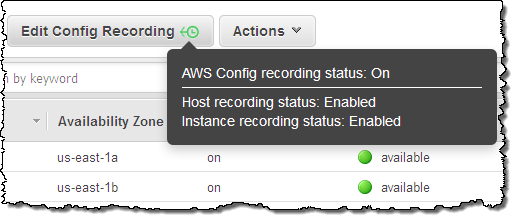
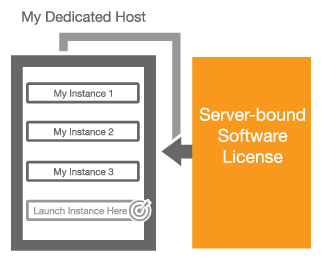 ライセンス持ち込み(Bring Your Own Licenses) – サーバ単位の既存のライセンスであるWindows Server, SQL Server, SUSE Linux Enterprise Serverやその他のエンタープライズシステムや製品を、クラウドに持ち込めます。Dedicated Hostのソケット数や物理コア数を確認することができますので、実際のハードウェアに適するソフトウェアライセンスを取得し使うことができます。
ライセンス持ち込み(Bring Your Own Licenses) – サーバ単位の既存のライセンスであるWindows Server, SQL Server, SUSE Linux Enterprise Serverやその他のエンタープライズシステムや製品を、クラウドに持ち込めます。Dedicated Hostのソケット数や物理コア数を確認することができますので、実際のハードウェアに適するソフトウェアライセンスを取得し使うことができます。